Scrape launches from SpaceX website with Beautifulsoup and Python
What is web scraping ?
Web scraping is a technique for extracting data from websites. It can be a useful tool for research, data analysis, and other purposes.
BeautifulSoup with Python
One of the most popular libraries for web scraping in Python is BeautifulSoup. In this article, we will learn how to use BeautifulSoup to scrape data from a website using Python.
First, we need to install BeautifulSoup and other libraries for our script. To do this, run the following command in your terminal:
pip install beautifulsoup4 requests lxml
Next, we will import the necessary libraries in our Python script:
from bs4 import BeautifulSoup
import requests
Now, we will use the requests library to send a request to the website we want to scrape. We'll store the response in a variable named response.
url = 'https://www.example.com'
response = requests.get(url)
We can check the response's status code to ensure the request was successful. A code of 200 indicates success.
if response.status_code == 200:
print('Success!')
else:
print('Something went wrong.')
Now, we will use BeautifulSoup to parse the HTML content of the response. We will create a BeautifulSoup object called soup and pass in the HTML content and the parser that we want to use. In this case, we will use the lxml parser.
soup = BeautifulSoup(response.content, 'lxml')
Now that we have a BeautifulSoup object, we can use various methods to extract the data that we want from the website. For example, we can use the `find` method to find a specific element in the HTML content.
title_element = soup.find('title')
title = title_element.text
print(title)
We can also use the find_all method to find all occurrences of a specific element in the HTML content. This method returns a list of elements that match the specified criteria.
link_elements = soup.find_all('a')
links = []
for element in link_elements:
links.append(element.get('href'))
print(links)
We can also use CSS selectors to find elements in the HTML content. For example, we can use the select method to find all elements with the class news-item.
news_items = soup.select('.news-item')
for item in news_items:
print(item.text)
Scraping SpaceX Launches
Now, let's try a real example of scraping. We will obtain a list of all the launches conducted by SpaceX.
First, we take a look at the source code of the page we are targeting. spacex.com/launches
Right-click on the page and inspect to get something like this.
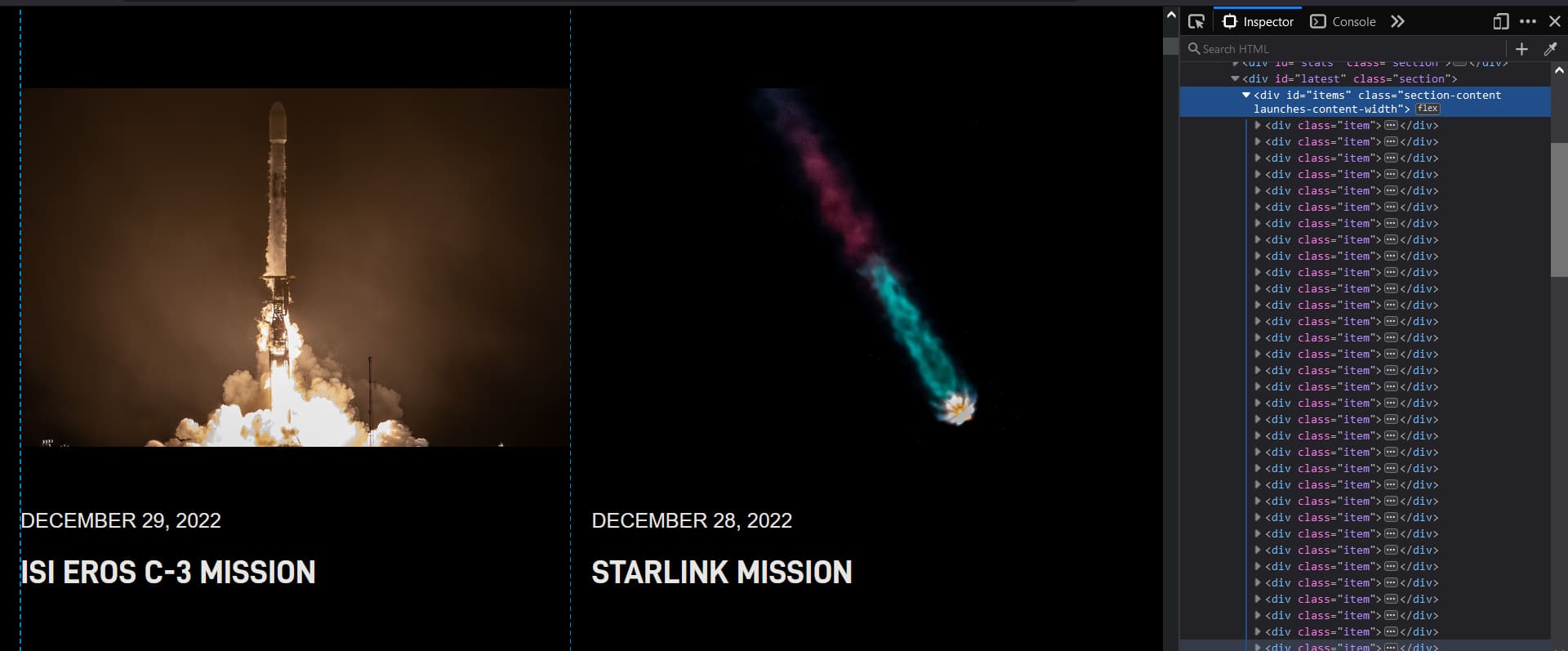
On the right, you can see the selected `div` with the `id` of `items`. That's the data we want.
We can scrape all launches and print the date and mission name in the terminal with this code.
from bs4 import BeautifulSoup
import requests
url = 'https://www.spacex.com/launches/'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'lxml')
launches_container = soup.select_one('#items')
launches = launches_container.select('.item')
for launch in launches:
date_element = launch.select_one('.date')
date = date_element.text
label_element = launch.select_one('.label')
label = label_element.text
print(f'Launch date: {date} Label: {label}')
else:
print('Something went wrong.')
Here's the structure of the code of the launches in the page
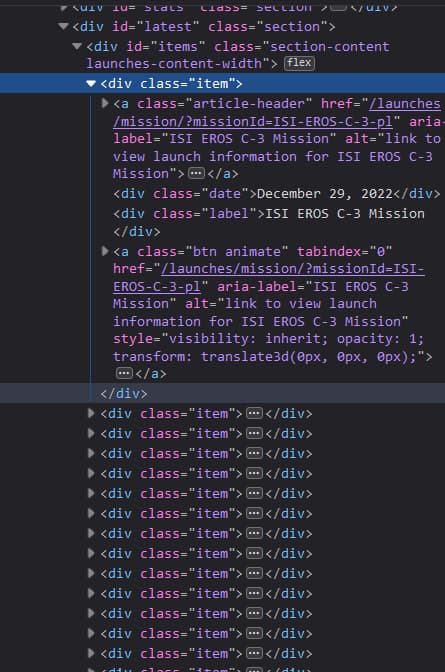
There are multiple methods and techniques for scraping data from a website using BeautifulSoup and Python. With practice and experimentation, you can extract the data you need from almost any website.
I hope this article has helped you understand how to use BeautifulSoup to scrape data from a website with Python. Wishing you success in your scraping endeavors!
Export to CSV
The goal for scraping data is to use it in something useful, so we should export it, for example, to CSV because it is easy to work with and well supported.
First we need to import csv to our python script
import csv
We can create a CSV file to store data using the `open()` function. This function enables us to open a file and read or write from it. To work on a file, we need to provide it with a name and a mode. The mode is a string that indicates whether we want to read, write, or use other modes.
And it's important to close the file when you're done working on it, here's an example
file1 = open('file1.txt', 'w')
file1.close()
We can use the `with` statement to automatically close the file when we're done. This is the approach we'll take.
Next, the CSV part, we need a writer function to write the rows in the CSV file.
with open('spacex-launches.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f, delimiter=';')
writer.writerow(['Launch date', 'Label'])
This code creates the file, specifying the mode as writing and the encoding. Initialize the writer, specify the delimiter as a semicolon and write the first row, which will serve as the header for the CSV file.
We can now integrate this into our code like so:
from bs4 import BeautifulSoup
import requests
import csv
url = 'https://www.spacex.com/launches/'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'lxml')
launches_container = soup.select_one('#items')
launches = launches_container.select('.item')
with open('spacex-launches.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f, delimiter=';')
writer.writerow(['Launch date', 'Label'])
for launch in launches:
date_element = launch.select_one('.date')
date = date_element.text
label_element = launch.select_one('.label')
label = label_element.text
writer.writerow([date, label])
else:
print('Something went wrong.')